
|
最近几年一直参与大数据产品的研发,同时大数据产品在海量数据场景下其处理性能又是其主要卖点和突破,所以个人在这几年经常忙于如何对大数据产品进行性能上面的优化,并且想通过本文和大家聊聊具体的几种比较常见大数据性能优化技术。  常见的大数据性能优化技术一般分为两部分,其一是硬件和系统层面的观测,从而来发现具体的瓶颈,并进行硬件或者系统级的调整;其二是主要通过对软件具体使用方法的调整来实现优化。 硬件方面的监测   图1. Windows7性能指数 关于硬件性能本身,个人觉得最好对性能的诠释就像图1大家比较熟悉的Windows7操作系统性能指数所展示的一样,性能本身并在于其所长,而是在于其所短,就像图1里面那个5.4分主硬盘托了整体的后腿一样,只要有短板存在,其他地方再强也可能收效甚微,所以需要硬件的性能检测就是找出短板在那里,并且尽可能地找到应对的方法。 在硬件观测角度方面,主要通过以下四个维度来判断到底哪里是瓶颈,它们分别是CPU、内存、硬盘还有网络。 CPU利用率 首先,在讲检测CPU性能之前,我们可以通过这个“cat /proc/cpuinfo |grep “processor”|wc -l”命令来获取本机的核数(如果开了超线程,一个核可以被看作两个核),这样可以知道CPU利用率的上限是多少。 最常用CPU监测工具是TOP,当然TOP输出是一个瞬间值,如果想获取精确的数据,需要持续关注一段时间。 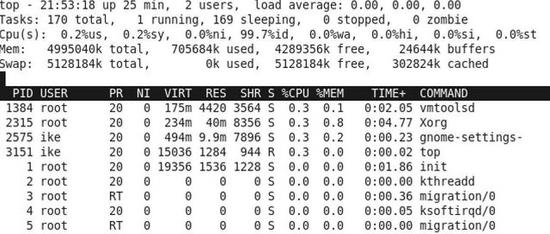 图2 TOP示例 TOP的使用主要看两个值,其一是总体使用值,其最大值是100%,就是图2第三行Cpu(s),前面两个0.2%分别是用户态和内核态的利用率���而99.7%是CPU空闲率,从这个可以看出,本机的CPU部分基本是空闲的;其二可以看相关进程,看它的“%CPU”使用率,比如,Xorg这个GUI进程的占用率是0.3%,但是这里面的100%不是本机所有CPU的100%,而是单个核的100%。所以它的上限会是本机核数*100%。 图3 uptime示例 因为TOP主要关注的是瞬时的值,如果要看一段时间的均值,这个时候可以用uptime这个命令,见图3,它除了可以显示当前总运行时,当前在线用户,更重要的是可以显示1分钟、5分钟、15分钟的整机CPU的平均负载情况。 假设在平时监测的时候,如果经常碰到用满80%以上CPU资源的话,可以理解为CPU利用率高,在这种场景下大多数只能靠优化执行逻辑,才能提升效率。 内存的监测  图4 free -m的示例 关于内存的监测,常用的命令是free -m,通过这个命令可以查看系统内存的具体使用情况。其中total,used和free都很好理解,通过这三列可以看出此时系统总内存,已经使用内存和没有被使用的内存,而cached这列则表示有多少内存已经被Page Cache占用,但当系统内存吃紧的时候,Page Cache会立即被回收并分配给请求内存的应用程序,所以Page Cache也可以被视为处于free状态的内存。 还有下面的Swap分区,如果used数值比较高,说明内存非常紧张,系统已经动用交换区,同时IO开销也会增长非常明显。当发现内存不够用的情况,可以考虑重启或者关闭那些占用很多内存的进程。 (责任编辑:晨鸿) |
