
|
尽可能使用压缩和列存 对于一些新入门的工程师,也包括那些有很多传统关系数据库使用经验的专业DBA数据管理员而言,大家都对列存比较一知半解,从而不敢使用。 列存和传统行存相比,主要有两个比较大的区别: 其一是数据不是按照行来存储,而且是将很多行的数据按列归属在一起,并存储 ,具体可以看图9; 其二是一般行存的写入是一行行,而且列存是比较批量的,所以写入的数据库块会比较大,一般大于行存常见的8KB。基于我个人这几年的经验,列存在极大多数分析场景下,都能提升3倍以上的性能,除了���些需要遍历一个表半数以上列的场景。因为通过列存不仅能够通过避免那些不要列的导入,这样能减少硬盘的I/O总量。并且由于列存本身数据是一个大块一个大块的存在,所以是硬盘I/O读取操作的次数也会减伤,这个对于硬盘I/O非常有利,因为本身硬盘I/O单次随机读取操作的成本非常高,和SSD相比。但是批量连续成本却非常优秀,当然如果使用SSD的话,性能会更优。 在这个基础上,由于连续数据都归属于一列都比较类似,比如,性别,所以对其压缩的效果非常不错,一般在1比5左右,并且通过压缩节省的I/O远大于压缩和解压缩所带来CPU的损耗。这也导致就算所有数据全都在硬盘上,其性能的损失和所有数据在内存上面缓存相比,一般慢4到5倍左右,其他也不会特别亏。 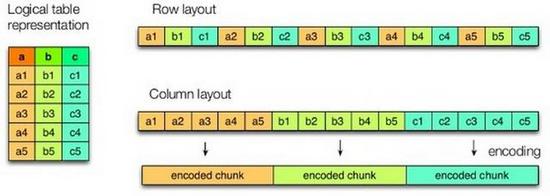 图9 列存和行存的对比 善加利用Page Cache 在上半部分已经提到了, 利用好Page Cache可以达到最基础级别的内存计算的效果,当然和真正意义上的内存计算还是很大的距离。在性能测试的时候,这个优化是比较常见的。一般作法是,先通过命令“sync; echo 3 > /proc/sys/vm/drop_caches”来清空page cache,之后跑一下比较简单,但又能加载所有相关数据的语句,比如,对每一列进行求总,这种做法的坏处是没有机会应对真实可能存在性能瓶颈,这对今后的实际运行会产生很多不可控的因素,因为真实业务场景肯定会比所预想到的场景更复杂。 利用好分区特性 众所周知,最快SQL就是什么都不做的SQL,比如,“select 1”;当然在实际的操作过程中,肯定不会有类似“select 1”这样没有意义的操作。所以对于传统关系数据库而言,为了减少读取不必要的数据,一般会使用索引。但是对于大数据这样分析操作而言,索引这种机制太昂贵,而且收效甚微。 分析大数据应用常用的过滤数据的方式是分区,特别是按照时间来分区,因为一般时间是最合适分割大数据的维度,比如,数据按照月分区,这样如果查询只需要涉及到某月数据,那么其余十一个月数据可以立刻忽略,当然如果按日来分区的,效果可能会更好,但尽量避免因为粒度太小,导致写入文件过于碎片化的情况。 Join的优化 对于大数据的分析应用而言,Join操作是非常常见的,并且Join操作本身对硬件的短板也更敏感,特别是网络,因为大多数的分布式操作,每个数据节点可以独立地完成,但 Join经常需要来自其他节点数据才能完成本节点的执行,并且这个量可能很大,有的时候,一个节点执行所需要的数据远超本节点自带的数据,类似场景还有unique这样的去重操作,所以在调优方面消耗的功夫也最多。 常见Join方式,主要有三种: 其一是Broadcast广播,常用于大小表之间的Join,Join发起方会将小表的相关数据完整地分发到每个数据节点,之后当每个数据节点收到小表之后,会找其本地的大表数据来完成Join的,如图10,pages是小表,visits是大表,发起方将Pages这张小表分发到每个数据节点; 其二是对小表Local化,这个机制本质上非常类似Broadcast,只是分发小表这个操作是做导入数据的时候自动完成,性能肯定比Broadcast更好,因为减少传输小表的网络消耗和等待时间,但是需要在创建表的时候,做一些额外的设置,这个机制在MPP数据是非常常见的,但是在Hadoop平台上面还是比较少见,因为其底层的HDFS分布式文件系统比较强调硬件无关,地址透明,这个和数据尽可能Local化的思路是违背的; (责任编辑:晨鸿) |
