
|
在这里稍微扩展一下Page Cache这个内存机制,因为这个机制对大数据挺重要的。一般在Linux系统上,利用默认系统I/O接口写入的文件块,会先在Page Cache上面有一个缓存,之后再写入到I/O设备上面,那么假设系统内存没有被占有满的话,在这种情况下,这个缓存会长时间保留,并不会被洗出内存,这样等下次程序访问到这些文件块的时候,肯定会访问Page Cache上面的那个版本,也就是直接访问内存,所以性能方面是内存级别的。 I/O性能的监测 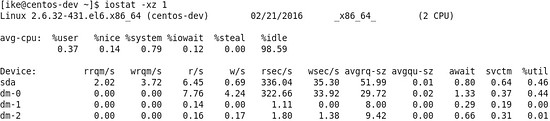 图5 iostat –xz 1示例 关于I/O性能,可以通过iostat这个命令来观察I/O的性能,具体见图5(sda是主硬盘),虽然参数比较多,但可以主要关注这两个参数: 其一是await,它代表了IO操作的平均等待时间,单位是毫秒,这也是应用和磁盘之间操作所要消耗的时间,包括等待和实际的操作,如果这个数值大,说明I/O资源非常忙或者有故障; 其二是%util,也就是设备利用率,数值如果超过60,所以利用率很高,并会影响I/O平均等待时间,如果到100,那就说明设备已饱和了,只能添加更多I/O资源。 网络方面的监测 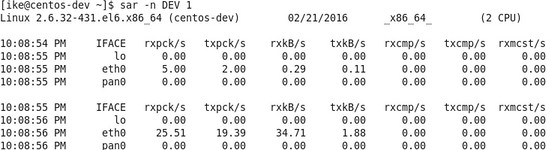 图6 sar –n DEV 1示例 在网络方面,使用的比较多的sar(System Activity Reporter)命令,如图6。这个命令可以查看网络设备的吞吐率,并在这个基础上,将吞吐量和硬件上限做对比,来判断网络设备是否已经饱和,假设以单张千兆网卡为例,如果“rxkB/s”和“txkB/s”两种相加超过100MB的话,说明网络已经接近饱和了。还有除了这个通过命令行来获取网络数据之外,还可以通过开源的nload的工具来进行监测,具体见下图: 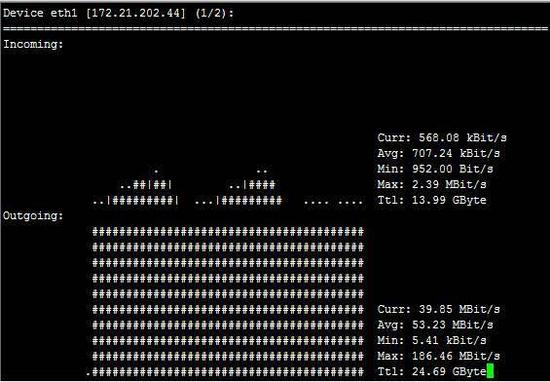 图7:nload示例 VMSTAT 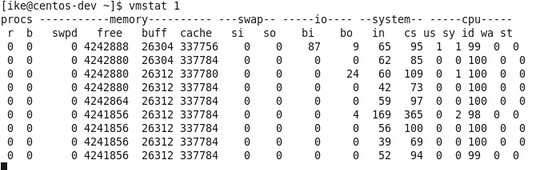 图8 vmstat 1示例 其实除了上面这些工具外,还有一个vmstat这个全能的命令,能监控硬件的方方面面,比如,如图8所示,Procs的“r”列,这个列显示正在等待CPU资源的进程数,这个数据比之前看的top和uptime更加能够体现CPU负载情况,并且这个数据不包含等待IO的进程。如果这个数值大于机器CPU核数,那么机器的CPU资源已经饱和。 Memory部分的“free”,“buff”和“cache”列的作用和上面free作用类似,而“si”和“so”说明使用Swap的次数,如果这个数据不为0,说明Swap交换区已经在使用,也意味着物理内存已经不足。 Cpu部分也大体和TOP上面显示类似,但可以关注“wa”这列,其代表的是IO等待时间,如果数值大于0的话,可以判断I/O资源有争抢。 如果通过上面硬件方面的监测,发现了瓶颈,或者发现了有很多余量,可以通过下半部分的软件方面的优化来进行调整,如果软件方面也无能为力的话,那么只能通过购买和安装更多的硬件。 软件方面的优化 这个方面因为各个大数据产品的实现方式不同,并且需要优化点也不同,操作方式更是不同,所以在这里,主要提供一些方针供大家参考。 写入优化 因为常见大数据产品的写入和传统关系型数据库是不同,传统关系数据库的写入是一行一行的写入,而常见大数据产品的写入是批量的写入,并且每次批量写入之后,都会生成新的数据文件,并且这个数据文件是不会被修改的。所以导入数据粒度小的话会导致很多细小文件产生,这样会导致更多的I/O操作,所以在使用大数据产品的时候,导入数据规模是越大越好,常见的规模在100MB以上为佳。 尽可能地并行 假设通过前面的硬件方面的测试方面,发现无论是CPU,内存,I/O还是网络,都没有遇到瓶颈,并且至少有20%潜力可挖,这个时候可以考虑尽可能地通过并行来提升性能,主要有两个方式:其一是每台机器上面部署更多的进程来压榨硬件资源;其二是提升单个进程的多线程数,这种方式比第一种更简单,风险也更低。总体而言,尽量使每台机器所使用到的线程数可以达到系统自身线程数的80%。 (责任编辑:晨鸿) |
