
|
其三是Shuffle或者Partitioned Join机制,其常用于两张大表之间的Join。因为将大表都分发给每个节点肯定成本太高了,而且数据节点的内存不一定能放的下这么多数据,所以通过Shuffle洗牌机制,也就是将所有参与的Join表的相关部分按照某种机制均匀分发到各个节点,并且每个节点数据都是独立的,如图11所示,pages和visits都是大表,它们按照Join列Hash的值来进行再次分布,节点1有Join列为A-E的数据,之后依次类推,虽然成本很高,但是对于大表之间的Join是最合理和最可行的方法。 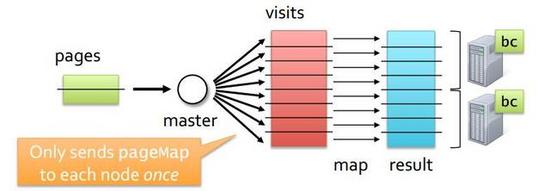 图10 Broadcast Join 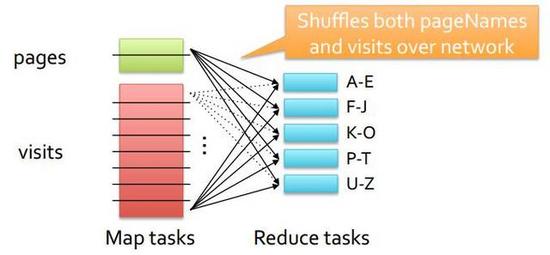 图11 Shuffle Join 介绍完Join机制之后,再深入一下Join的优化,也主要有三个方面: 其一是在大表和小表摆放顺序要符合技术规范,这样能避免优化器将大表作为Broadcast表来进行分发; 其二是开启或者执行预统计,也就是在查询之前,开启表的预统计,虽然预统计会耗费一点时间,但这样能够让优化器知道表的具体情况,从而做出合理的方案,即使之前表的顺序写错了,还有由于预统计会遍历数据,这样可以将数据预先加载到Page Cache上面; 其三是选择合理的Join机制,也就是做好Broadcast和Shuffle之间的抉择,两个大表之间选择Shuffle,如果不是选择Broadcast,当然假如优化器能判断出是更好不过了,但当优化器出现问题的时候,可以通过人工输入一些提示符来帮助优化器来判断; 多看Profile 介绍很多优化技术,但是这样技术都比较笼统,为了更好做优化,做某个产品优化,还是最好能多看看每次执行后的Profile,这样能对产品更深的理解。 因为大数据产品和技术比较多,并且每个产品和特色和设计都不同,所以在细节方面没有特别深入,但是的确有非常多的共性,所以通过硬件的监测,以及软件方面的优化,应该能把常见的大数据产品发挥到八成的功力。 参考资料: 1.用十条命令在一分钟内检查Linux服务器性能http://www.infoq.com/cn/news/2015/12/linux-performance 2.在 Linux/UNIX 终端下使用 nload 实时监控网络流量和带宽使用http://linux.cn/article-2871-1.html 作者介绍
吴朱华:国内资深云计算和大数据专家,之前曾在IBM中国研究院和上海云人信息科技有限公司参与过多款云计算产和大数据产品的开发工作,同济本科,并曾在北京大学读过硕士。2011年中,发表业界最好的两本云计算书之一《云计算核心技术剖析》。2016年和上海华东理工大学的阮彤教授等合著了《大数据技术前沿》一书。 (责任编辑:晨鸿) |
